
When your database starts to outgrow its capacity, you’ve got two options: scale up or scale out. Scaling up means buying bigger, beefier servers with more RAM, CPU, and disk space. Whereas scaling out (using MongoDB’s sharding feature) can be a more cost-effective and flexible solution.
The Basics of Sharding
In simple terms, sharding involves splitting your data across multiple servers. Instead of upgrading to more expensive servers, sharding allows you to use several smaller, more affordable ones. This doesn’t replace replication, which is still in play. However, instead of copying your entire dataset to each replica set, sharding distributes (or breaks up) chunks of your database to different replica sets.
Let’s say you have a massive collection of recipes. Rather than storing every recipe on the same replica set (and thus server), you could divide the data alphabetically by recipe title. For example:
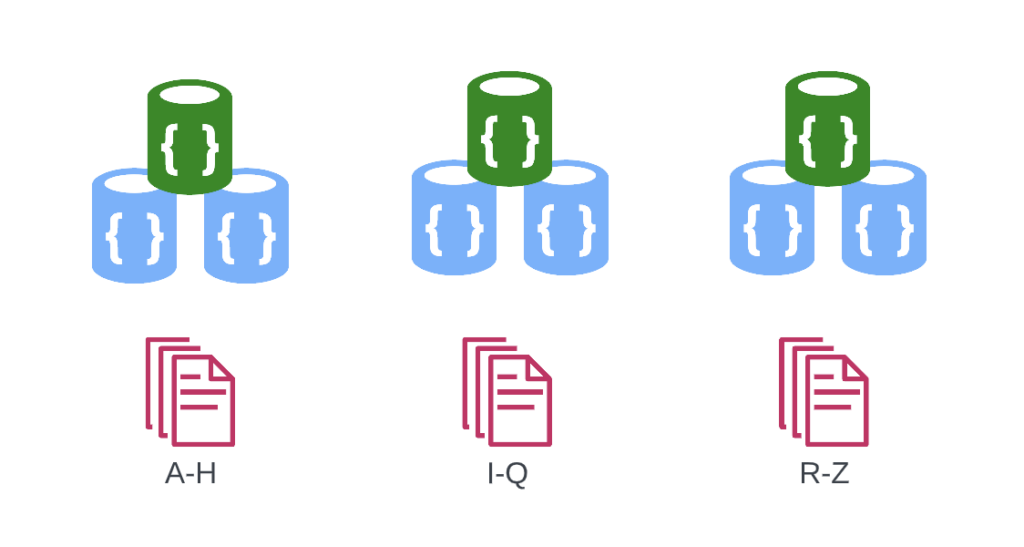
- Replica Set 1: Recipes A-H
- Replica Set 2: Recipes I-Q
- Replica Set 3: Recipes R-Z
This way, each server holds a portion of the database, and MongoDB ensures no one server is overloaded. As data grows, MongoDB can “rebalance” the allocations to keep things running smoothly. You can visualize this setup using the diagram below. We have three replica set clusters, each with three nodes, and each replica set is responsible for storing its range of recipes. Each cluster is now referred to as a “shard“:
Shard Keys: How to Split Up Your Data
The magic behind how your data is split lies in the shard key, which is the field (or fields) that tells MongoDB how to distribute the data across your servers. In our recipe example, the shard key is the recipe title. Choosing the right shard key is crucial to ensure even distribution and performance.
Config Servers: The Brain of Your Sharded Cluster
Now that we’ve split our recipes across multiple shards using the recipe title as our shard key you might be wondering, how does MongoDB know where to find a specific recipe? That’s where config servers come in.
Config servers store what is referred to as the “metadata” about the cluster (or shard), including the mapping of shard key ranges to specific shards. In other words the list of which shard has a particular document, based on its title. When a query comes in, MongoDB first checks the config servers to determine which shard(s) hold the relevant data.
For example, if you are looking for a recipe titled “Italian Wedding Soup” MongoDB would do the following for you:
- Query the config servers to check which shard contains recipe, which would be the shard with the
I-Qrange. - Route the query directly to that shard which is Replica Set 2, thus avoiding lookups on the other shards.
- Retrieve the recipe document, and return it to the client.
Balancing Your Data
In our example we used a pretty simple distribution method based on title, depending on your data this can probably be spread out amongst your three shards pretty easily as we showed above with A-H, I-Q and R-Z. However it is possible this might become what we called “imbalanced” over time.
Balancing The Imbalance
Image this scenario: Our recipe site acquires another recipe site and all its recipes, great more recipes!
However there is a bit of a downside for our sharding method, the new site we acquired has named nearly all their recipes starting with the word “The” or “Best” as the first word, as in “The Best Beef Stroganoff”, or “Best French Toast Ever”. This use of the words “Best” and “The” means we have added thousands and thousands of recipes to our A-H and R-Z range shards which has made those shards have way more recipes than our I-Q shard.
Luckily MongoDB’s balancer process (which is automatically managed via the config servers) can migrate chunks between shards to maintain even distribution. We call this process “rebalancing”. So, the config server might change our ranges to A-B, C-S and T-Z thus balancing out our data again! We’ll discuss this concept more later.
By maintaining a centralized record of the shard key ranges and cluster topology, config servers play a critical role in keeping your sharded database organized, efficient, and scalable.
Conclusion
Sharding is a powerful tool for handling large-scale datasets, allowing you to distribute data across multiple servers efficiently. By breaking up our massive recipe collection using a shard key (in this case, the recipe title), we ensure that no single server bears the full burden of our growing database.
By leveraging sharding, replica sets, and config servers together, MongoDB provides a resilient, scalable solution for growing applications. Whether you’re managing thousands or millions of recipes, this architecture ensures your database remains fast, efficient, and ready to scale with your needs.
In the next few parts, we’ll dive deeper into:
- Shard key selection
- Balancing and other best practices
- The basics of setting up your shared setup
Stay tuned, and as always checkout the other content here to learn more about MongoDB!
