
In our previous post, we covered the basics of sharding (how MongoDB distributes data across multiple servers), why config servers are critical, and how balancing helps maintain efficiency.
Now, we’ll go deeper into three critical areas that will determine whether your sharded cluster thrives or struggles:
- Choosing the right shard key – Avoid common pitfalls to make sure your queries fast and efficient.
- Keeping your cluster balanced – Prevent bottlenecks and ensure smooth operation as your data grows.
- Setting up your sharded environment properly – Build a foundation that scales with your needs.
Let’s break these down in detail.
Shard Key Selection: The Most Important Decision
Your shard key determines how MongoDB splits and distributes data across shards. Choose wisely, and your system will be scalable and efficient.
Choose poorly, and you could face slow queries, uneven load, and performance bottlenecks.
What Makes a Good Shard Key?
A good shard key should have:
✅ High Cardinality – Many unique values to evenly distribute data across shards.
✅ Even Distribution – Ensures that no single shard is overloaded while others sit idle.
✅ Query Efficiency – Common query patterns should target a single shard, not all of them.
✅ Low Update Frequency – If a document’s shard key changes, MongoDB must move it, which is expensive.
Examples of Different Shard Keys
| Shard Key | Good or Bad? | Why? |
|---|---|---|
userId | ✅ Good | High cardinality, spreads data evenly |
createdAt (Date field) | ❌ Bad | Newer data will always go to the same shard (which will overload it) |
region (small set of values) | ❌ Bad | Low cardinality, data might be unevenly distributed |
email | ✅ Good | High uniqueness, spreads well across shards |
💡 Pro Tip: Consider compound shard keys (e.g.,
{ category, createdAt }) if a single field doesn’t meet all the criteria.
Balancing and Best Practices
Even with a well-chosen shard key, data can become unevenly distributed over time. MongoDB’s balancer process helps by migrating chunks between shards.
How Balancing Works
1️⃣ Detects imbalance – MongoDB identifies shards with too much data.
2️⃣ Moves chunks – The balancer redistributes chunks to keep things even.
3️⃣ Adjusts dynamically – As data grows, MongoDB continues balancing in the background.
Best Practices for Keeping a Balanced Cluster
✔️ Pre-split your data – If you expect rapid growth, manually split chunks ahead of time.
✔️ Monitor chunk migrations – Use sh.status() and balancerWindow settings for control.
✔️ Avoid large document moves – Updating a shard key moves a document to another shard, which can be costly.
✔️ Watch for hotspots – If one shard handles too many requests, rethink your shard key.
Setting Up Your Sharded Cluster
Once you’ve chosen a good shard key and understand balancing, it’s time to set up your sharded environment.
Below you can see a basic example of a sharded setup:
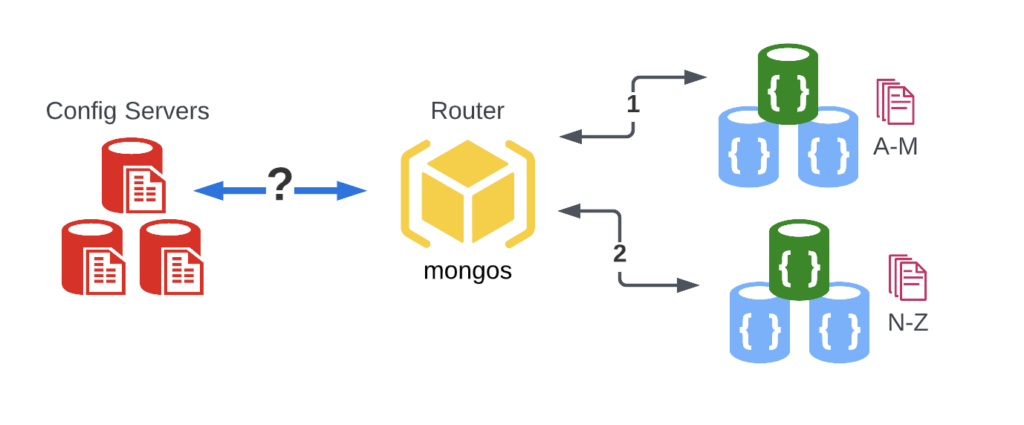
Note: A detailed breakdown of setting up a shared setup is beyond the scope of this post, but we will delve into each basic step to give you a high level understanding. Additionally this assumes you have already installed and/or downloaded all the necessary binaries.
Make sure to checkout the official docs for more detailed information.
Step 1: Deploying Config Servers (The Brain of Your Cluster)
To run a sharded setup at least three config servers are required, these store metadata about which shards hold what data.
From the Docs: “Config servers store the metadata for a sharded cluster. The metadata reflects state and organization for all data and components within the sharded cluster. The metadata includes the list of chunks on every shard and the ranges that define the chunks.”
Why config servers?
You might be asking yourself, why exactly do we need config servers?
Think about it this way: Have you ever stayed at an Airbnb (or other guest house) with a kitchen and when it came time to make a meal you find yourself opening all the different cabinets and draws to find the things you need? Well that is rather slow and frustrating isn’t it?!
Imagine instead if there was a Master List:
- Large pots in Cabinet 1
- Spoons in Drawer 2
- Mixer on the top self of Cabinet 4
- Cinnamon on the third rack of Cabinet 6
That’d make things a lot easier! This is basically what config servers do; they keep a master list of where each document is, based off your shard key … so MongoDB can find your document quickly!
Setting up config servers
To start a config server you will run a version the following command, on three different servers:
$ mongod --configsvr --replSet configReplSet --port 27019 --dbpath /data/configdbNote: Make sure to use the same replica set name, in this example
configReplSetas you setup each node. Also note we’ve used a different port of27019, which can allow us to run a config server node on the same server as other processes likemongodfor example.
After each config server is setup you can connect to one them (it doesn’t really matter which one) and initiate the replica set of config servers:
> rs.initiate({
_id: "configReplSet",
configsvr: true,
members: [
{ _id: 0, host: "config1:27019" },
{ _id: 1, host: "config2:27019" },
{ _id: 2, host: "config3:27019" }
]
})Once this runs, your config server(s) are online and tracking the metadata.
Step 2: Deploying Shard Servers
Next we’ll setup our instances for our shards. Each shard is a replica set, meaning it has multiple servers replicating the same data for redundancy.
🔗 If you want to know more about replica sets, and Replica Sets: Member Roles and Types
For each shard you’ll setup a mongod instance with a command something like this:
$ mongod --shardsvr --replSet shard1 --port 27018 --dbpath /data/shard1Note: Again, make sure to use the same replica set name for each shared as you set up its three nodes.
And then initiate that replica set:
> rs.initiate({
_id: "shard1",
members: [
{ _id: 0, host: "shard1a:27018" },
{ _id: 1, host: "shard1b:27018" },
{ _id: 2, host: "shard1c:27018" }
]
})Repeat this process for each additional shard (shard2, shard3, etc.). Now, your cluster has data storage nodes ready to be used!
Step 3: Deploy a mongos Router
Next you’ll need to setup what is known as the “query router”, this process will direct queries to the correct shard. For this we’ll use the mongos binary and provide it with information about our shards. The mongos router is what applications connect to.
Note: The
mongosprocess doesn’t store data. Instead, it checks the config servers to find the right shard and forwards queries to that shard’smongodprocess.
An example of how you might setup your mongos is as follows:
$ mongos --configdb configReplSet/config1:27019,config2:27019,config3:27019 --port 27017Note that we sent the host and port number of each replica set, hear called config1, config2config3
💡 Pro Tip: Your applications will connect to
mongosjust like they would connect to a normal MongoDB instance (that’s why we put it on port27017.
Step 4: Enable Sharding on Your Collection
Now that your shards, config servers, and routers are ready, you can enable sharding for your database.
> sh.enableSharding("myDatabase")
> sh.shardCollection("myDatabase.recipes", { "title": "hashed" })Final Checks: Testing Your Sharded Cluster
To verify everything is working, run:
> sh.status()You should see output showing:
✅ Config servers online
✅ Shards properly registered
✅ Collections successfully sharded
That’s it! Your cluster is now sharded, balanced, and optimized for scale. 🚀
Wrapping Up
Sharding in MongoDB is powerful, but success depends on:
✔️ Picking the right shard key to prevent performance bottlenecks.
✔️ Monitoring and balancing data across shards.
✔️ Setting up your cluster correctly with config servers, shards, and routers.
In the next post, we’ll explore common pitfalls in sharding and how to fix them as well as ways to monitor and get information about your shared server setup. Stay tuned.
🔗 Read more here: Scaling MongoDB with Sharding – The Basics
